
In this series of posts, our engineering team talks about the inner workings of Bubble, the cloud-based visual programming language that’s making programming accessible to everyone. If you’re interested in joining the no-code revolution, see our list of open positions.
In the previous Building Bubble post, we talked about the abstraction layer we built around Bubble’s JSON-based Abstract Syntax Tree. Rather than working with the tree directly, we wrap it in a class that represents a pointer to a location in the tree.
This level of indirection lets us load parts of it as needed, without the code that reads it needing to understand what data we have and what data we are still waiting on. Additionally, the fact that it’s just JSON under the hood means that sending chunks of a Bubble application around is super easy. We use the javascript built-in functions JSON.stringify and JSON.parse to send them over the internet.
That ease of sending data around, however, comes with consequences. This post explores one particular consequence of storing Bubble apps as JSON data, and how we dealt with it.
In object-oriented programming, there’s a distinction between an object’s interface — the set of behaviors it exposes to the outside world — and an object’s state — the internal data the object needs to remember in order to implement those behaviors. For example, if you have a Vehicle class, the interface might be methods such as driveTo(coordinates), currentSpeed(), loadPassenger(occupant), unloadAllPassengers(), and so on. The state, on the other hand, might be variables named currentCoordinates, currentVelocity, currentPassengers, vehicleType, and vehicleAcceleration.
State and interface are always somewhat in tension with each other. From the perspective of the interface, every different class of object is unique. It has a distinct set of behaviors that express what the object represents and how it functions in your codebase. For instance, a subclass of Vehicle might be Car, which might have methods like callShotgun(passenger), installBabyseat(), etc., whereas another sub-class might be Bike, which might have doAWheelie(), lockToRailing(), and so on. The more differentiated your classes are, the more useful they are.
In contrast, state wants to be uniform. The more structured state is, the easier it is to transport it and to store it. The code that is saving and loading your data does not care and does not want to care that one of your Vehicles is a Car and one is a Bike. It wants to be able to treat them identically. It’s a lot like a moving company: it wants everything packed in boxes, so it can stack the boxes in a truck and drive them off. The more things there are that don’t fit neatly into boxes, the more work it has to do to move them.
Traditional object-oriented programming is all about making interface-building really pleasant, at the expense of dealing with ugly problems around state. In fact, there is a whole category of software called Object-Relational Mapping (abbreviated ORM) tools, designed to deal with the messy work of taking your artisan, hand-crafted classes and chopping them up into uniform INSERT, UPDATE, and SELECT statements that you can send to your database. And like most moving companies, ORMs basically get the job done, but some of your stuff might be a little worse for wear at the end of the process. Queries they produce are often not as efficient as hand-written SQL, and getting the database tables to match up cleanly with your class hierarchies is often painful.
Because we designed the Bubble AST from the ground up to be easy to store and transmit, we had the exact opposite problem. Our state was really easy to work with, but our interface wasn’t differentiated enough. Everything in Bubble was represented as a tree of JSON data, with all the internals on full display, instead of wrapped in interfaces specific to the class of thing we were dealing with.
A Bubble application has pages, which contain visual elements, such as text boxes, inputs, and pictures. Some of these elements, such as groups, can contain other elements. There are also workflows, which consist of events followed by actions. The natural structure of a Bubble application looks something like this:
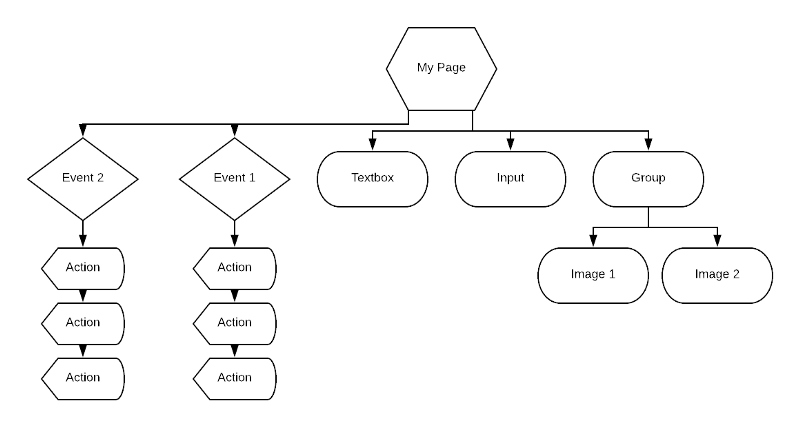
But the tree represented by our JSONBase classes looked more like this:
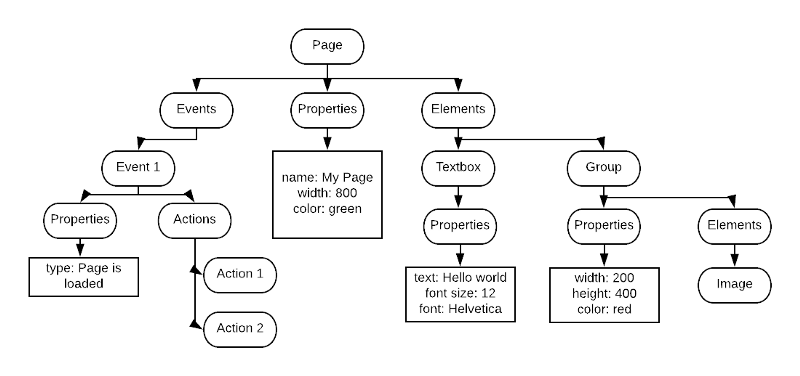
Rather than nice, clean abstractions we had a messy tree with a bunch of intermediate nodes and exposed state.
What to do?
Back in 2006, 6 years before Bubble’s launch, John Resig wrote a little library called jQuery, which by the time we started working on Bubble had taken the web development world by storm. In a way, he was solving a somewhat analogous problem. Web browsers expose the HTML of web pages to javascript as a tree, known as the DOM, which is clumsy, low-level, and annoying to work with directly. jQuery lets you take one or more DOM nodes, and wrap them in a jQuery object. You can then work with the jQuery object directly, which makes it dead simple to add, remove and alter HTML.
We decided to take a similar approach: we built a second abstraction layer that wraps our JSONBase classes. In homage to jQuery, we call it AppQuery.
Each AppNode in AppQuery behaves like a traditional object-oriented class. It exposes methods specific to the type of the thing the node represents: for instance, there are different AppNode sub-classes for Events, Actions, Elements, and Expressions, all with unique methods.
Each AppNode wraps a JSONBase object, which indicates where in the tree the AppNode’s data is stored. But AppNodes provide their own set of navigation functions that allow jumping over intermediate JSONBase nodes. For instance, Element nodes have an elements() method which returns an array of all the child elements that are inside it: for instance, a textbox contained inside a group. At the JSONBase level, this function is actually jumping down two levels: first to an intermediary node that represents the list of all child elements, and then to the node that represents each child element. But from the AppNode perspective, we can navigate the tree without needing to know that the intermediary node exists.
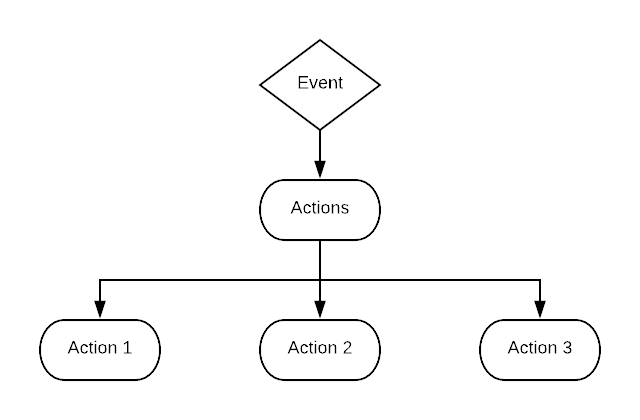
This has helped us out a number of times. For example, when we first built Bubble, we stored workflows as a linked list of actions:

Each event had an actions() method that would recursively walk the list and return all the actions in the workflow as an array, and each action had a next() method that returned the subsequent action in the workflow.
However, we discovered that we had a big problem: the database we were storing application data in at the time had a maximum nesting depth for JSON objects. One of our users had a very long workflow, and each time he would add a new action to it, he wouldn’t be able to save his app!
To deal with the problem, we rearranged the way we stored actions into a flat list:
At the JSONBase level, the tree looks totally different. But at the AppQuery level, it was only a couple minutes of work to rewrite actions() and next() to work with the new data structure. We were able to roll the change out within a couple of days, and our user went back to building his workflow.
Once again, good abstraction layers saved us from a potential technical nightmare. By having a outer tree, representing the semantic meaning of each node, that sits on top of the inner tree, representing the state of each node, we’ve achieved a compromise between the competing demands of interface vs state. We can do both high level operations (“run this workflow”) and low level (“save the user’s changes to their app to the database”), working at the right layer of abstraction for each.
Found this interesting? We’re always looking for great engineers to join us!
Build for as long as you want on the Free plan. Only upgrade when you're ready to launch.
Join Bubble



